White paper

The most of material world around us is anonymous, faceless, “disconnected” from its creators. Aside of inventors of the world’s prominent products of mass production, there are billions, and ever growing amount of objects of the material world that are designed, built, manufactured by almost everyone on the planet. The most common work outcome in product development and manufacturing is incremental upgrades and continuous development.
Millions of engineers and workers do incremental developments of the products and services in all industries worldwide. If employed, the records of who did what belong to employers in a technical and other kind of business format. Oftentimes information is a subject of confidentiality agreements, and normally such records don’t become a public domain even if not legally protected at some point of time. If self-employed, there could be no records, unless the work outcome is some kind of a recognized piece of art, design, performance, recorded for sale purpose. In general, material world built around us is impersonalized. Thanks to technology developments, in XXI Century millions of people on Earth leave digital fingerprints of their personality dimensions – personal lives, social activities, professional work and its outcome. For centuries to come, historical facts of our modern life have all technical means to be preserved for future generations as long as civilization on Earth exists.
Humankind is about to learn much more about itself by digitizing the entire world around us.
We are a mix of biology, inherited in genes and environmental influences family, social group, education, social class standing in the community. There are some kind of correlations between the individual’s biological “nature” and personal characteristics (traits), preferences, values, religion, insights on life.
“White men cannot jump”, “Italians are good singers”, “African Americans are the best in basketball” – this kind of statements are quite common, but are there scientifically proven and statistically sufficient datasets to qualify how accurate such assumptions can be?
The Problem
Possibilities to establish new correlations between human complete genome sequencing parameters, and individual’s characteristics that can’t be determined by environmental influences (intervention studies), become more affordable. However, obtaining relevant, side-by-side datasets of such parameters for the same massive of research participants is prohibitively expensive, and oftentimes impossible. Those, who provided their bio material for DNA test, may never agree to provide other relevant information about them. It seems unlikely that the ultimate solution may exist. Another problem is that for new, unexpected correlations it is difficult to predict what kind of information may constitute relevant dataset. For example, at the time of planning research, scientists could only guess that the correlation between genome characteristics and educational attainment will be established. In other words, it is difficult to obtain genome characteristics and variety of all kind of could-be-relevant information from statistically sufficient massive of research participants at the time when DNA data obtained. More
Partial solutions
Partial solutions can be sought on the paths of the purpose (application) of research that make sense for participants. Genealogical applications take a lead today.
One of the partial solution is the I@Work application, aimed for the job market. It allows users to record their lifetime work outcomes (products and services they were working on). The prototype can be seen at iwo.bio. We believe there is a value for an individual, either employed or not, to keep records on what he or she had done at work in some organized format.
ASSOCIATION BETWEEN HUMAN BRAIN (HIPPOCAMPAL GRAY MATTER PROBABILITY) AND INCOME
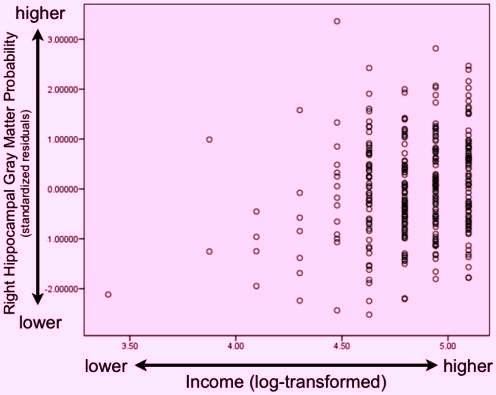
Prior Art
In the new era where we are moving into, various types of data will be collected over the lifetime. Today’s “life data ecosystem” concept is aimed to build a platform to establish an economy for exchanging genetic data and other biological information.
I@Work is proposing users to enter their records as a donation. To incentivize users, 1st Startup USA will provide users in-app DNA sequencing promotions and partnership perks from biotech firms, in exchange to the access for biotech researchers to users job outcome related data. For those who prefer to keep their data confidential, anonymous sequencing is available. For researchers, this solution will enable side-by-side DNA datasets with the relevant parameters of the same statistically sufficient massive of I@Work users that implicitly become research participants.